

A bit of a late happy new year to anyone reading this when it actually gets uploaded. As they say, better late than never I suppose.
This diary statistical analysis actually started a while ago. Off the top of my head it’s been about a year or two since I last worked on Theoretical Diary? But the app contained several ways of displaying entry statistics so here are a few pictures of how it was displayed.
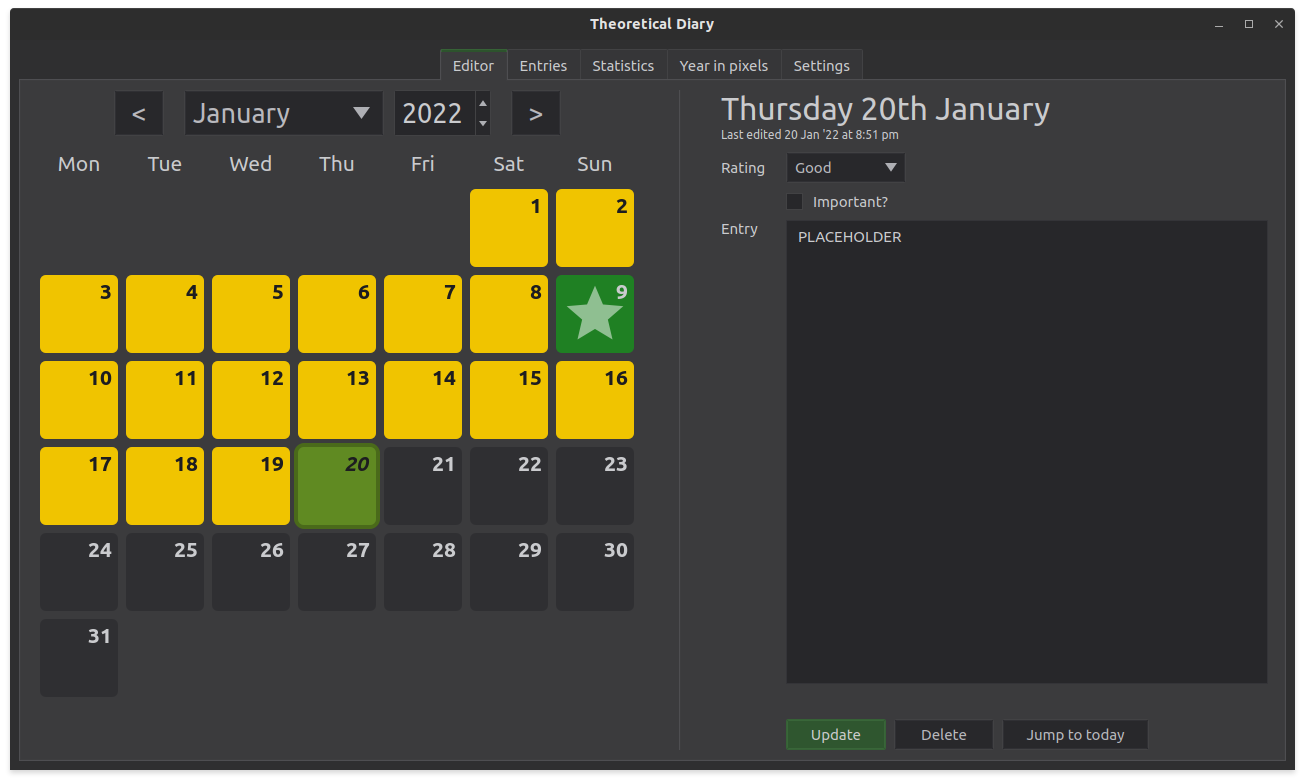
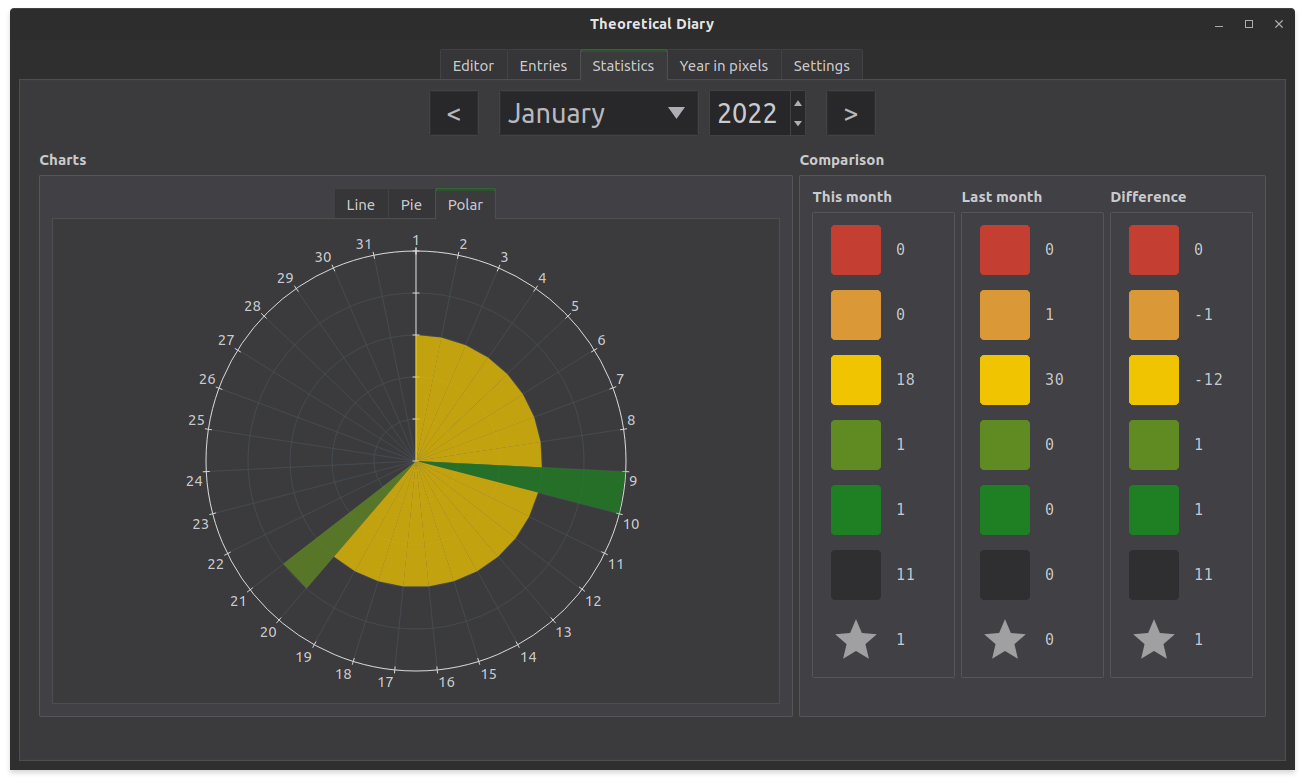
The last image features the “pixels” which was the main feature which I wanted to add. Near new years every year, I see a few reddit posts where people have recorded their ratings for each day of the entire year. And that’s the original reason I started using MoodFlow. It’ll pop up again.
But then I moved to obsidian as it featured a better editor and I basically haven’t touched the Theoretical Diary since. A big part of the reason is that Theoretical Diary was based on the Qt framework and Obsidian is based on Electron and if it came to it I would rather work with webdev languages than wrangle C++ for a text editor. And since I would rather use Electron and Obsidian already exists, there was very little resistance to me adopting it. It’s a pretty well polished application.
The next visualisation I made was using Veusz. However, I had to first generate the data in CSV format which could be read by it. So I wrote up this script real quick to do that.
#! /usr/bin/python3
import os
def get_entry_paths():
paths = []
for path, _, files in os.walk("entries"):
# dd-mm-yy.md
for name in sorted(
files, key=lambda name: (name[6:8], name[3:5], name[0:2])
):
paths.append(os.path.join(path, name))
return paths
def main():
files = get_entry_paths()
with open("summary.csv", "w") as output:
for filepath in files:
with open(filepath, "r") as f:
filename = os.path.splitext(os.path.basename(filepath))[0]
words = len(f.read().split())
output.write(f"{filename},{words}\n")
if __name__ == "__main__":
main()
The script worked well enough but it was Veusz that turned out to be the bottleneck. This is the last image I generated using it before I switched to the next method which will be detailed later in the post.
Now this image is absolutely huge. It is 11811x5905 pixels which is probably why it choked Veusz when it was generating it. However, it does look kind of nice at least? Purple is a pretty nice colour.
Anyway, I (with a lot of help from ChatGPT) wrote another script using matplotlib to generate a better visualisation yesterday.
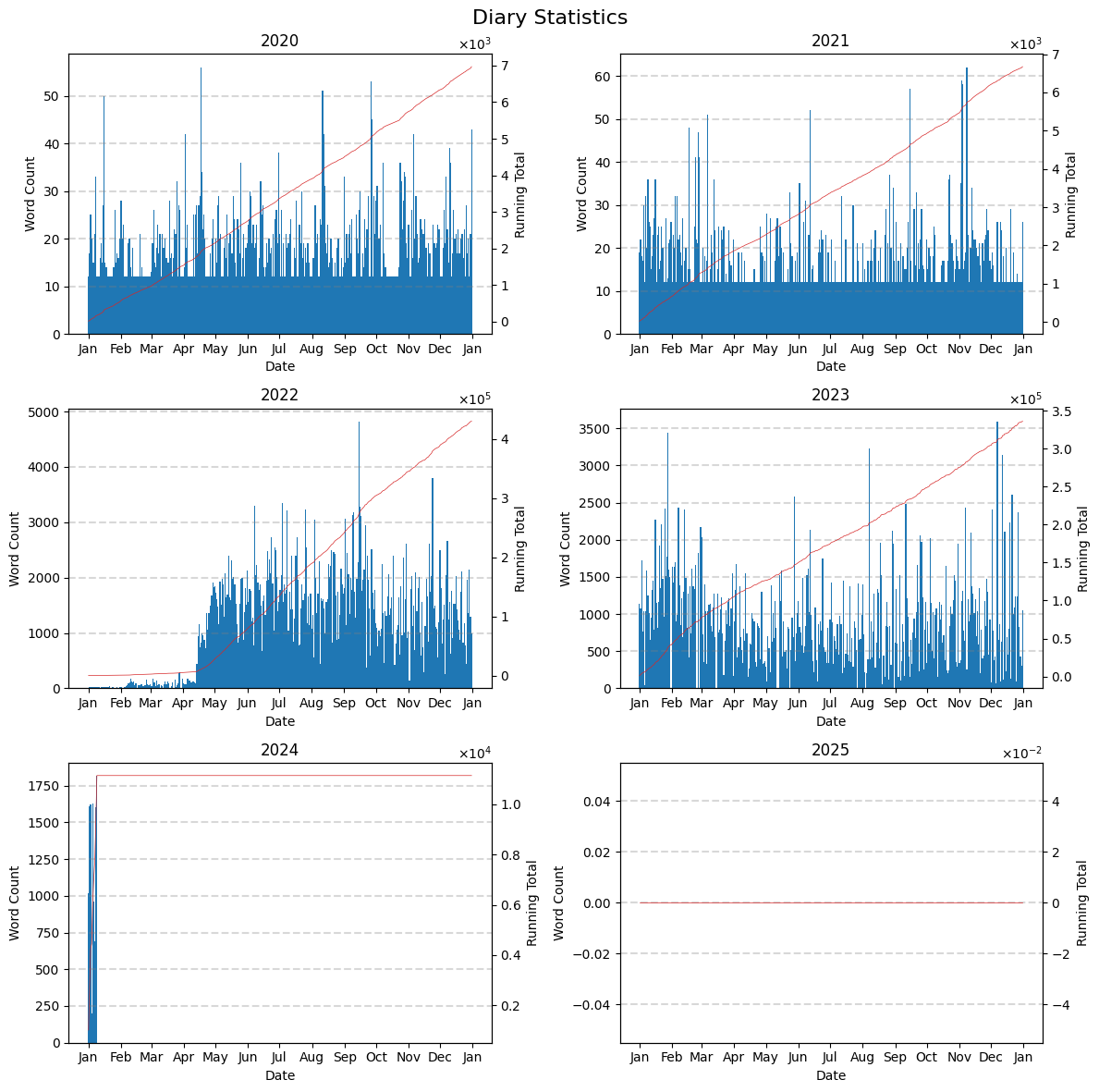
And here is one that uses a logarithmic scale. I generated this one purely for the sake of generating it. I don’t believe it presents the data better in any way.
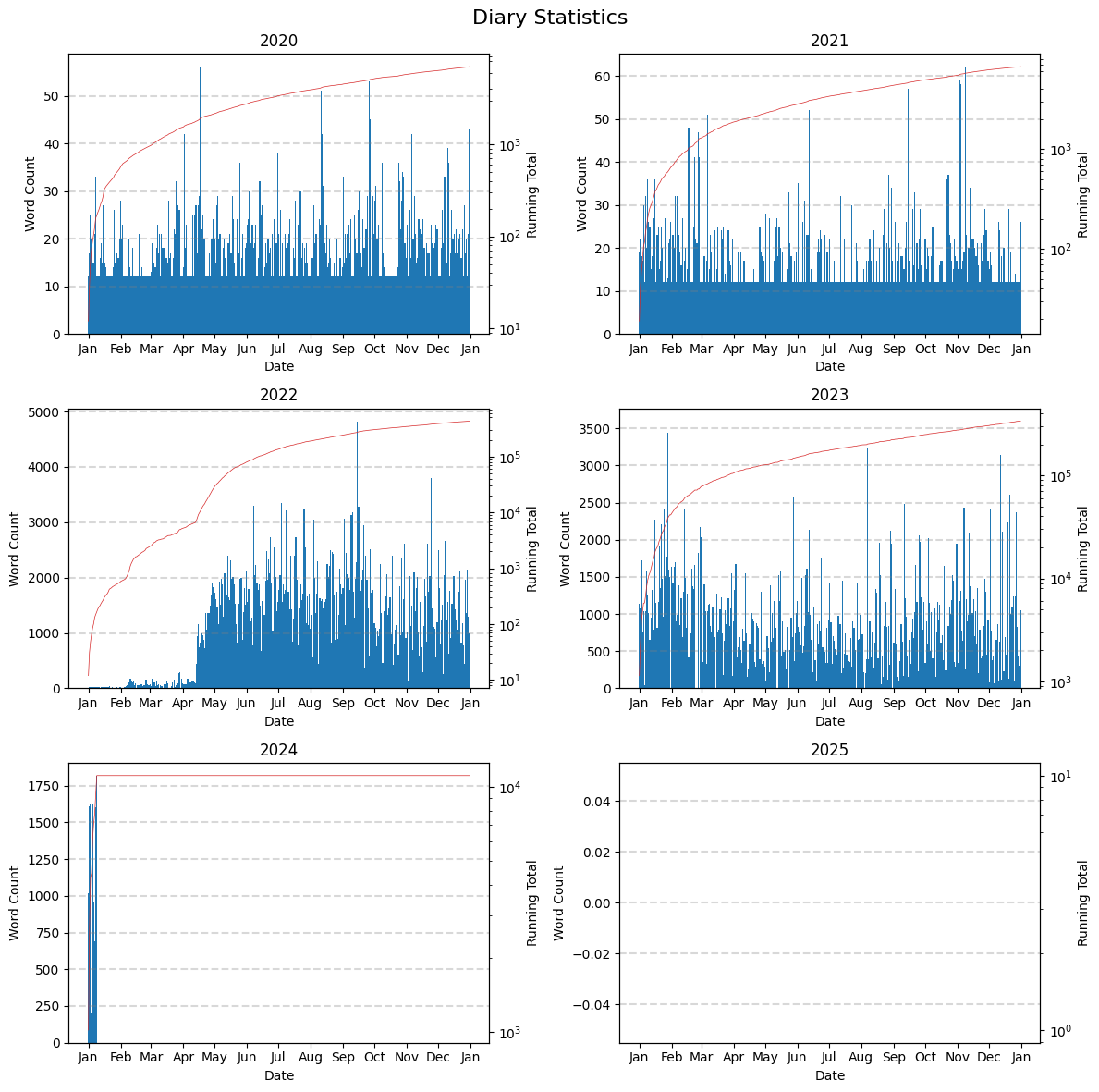
The weird solid bar at the bottom of the 2020 and 2021 plots has a bit of a complex backstory. Back then I used MoodFlow which allowed me to keep metrics like rating my mood every day. When I exported my MoodFlow data to Theoretical Diary I encapsulated those metrics which is why every day has at least 12 words. Those days where the br is flat at 12 just means I wrote no message for that day; I still left a rating however. This wasn’t an unusual occurrence back then.
When I exported my diary entries from Theoretical Diary into markdown format to use with Obsidian, another layer of encapsulation was added on top as Theoretical Diary stored data internally in a more complex format than what I had originally extracted from MoodFlow. It’s all kind of similar to how a packet gets encapsulated over and over again as each layer of the network stack handles it. However, you can’t really see this as by that time I was writing about 1000 words a day and you can’t really see a bar with height 50 on a graph whose maximum is at 5000 or 3500.
When I fully transitioned to Obsidian, there was no more encapsulation for new entries so that’s when you start seeing the gaps appear. I believe a few of those are due to me going on camping trips where I didn’t have access to a laptop. In those cases, I recorded audio entries for those days but I never bothered transcribing those, even with AI help. I don’t really write/narrate entries for the explicit sake of trying to jump back in time. I’m not even sure I have those recordings anymore.
The majority of the rest of those gaps come from me being too sick to write/record anything for that day. Those are way fewer though.
Then there are the two? days where I completely forgot to write an entry. Kind of sucks to break a streak like that but it is a bit surprising how fast one might move on from that. If you compute the reliability percentages, it’s still quite favourable.
Now there is one thing left which I haven’t discussed which is why I started writing longer entries all of a sudden after mid April 2022 but that’s a story for another day.
Anyway, that’s it for this post. Don’t know about the next one though 🙃
Reply by Email